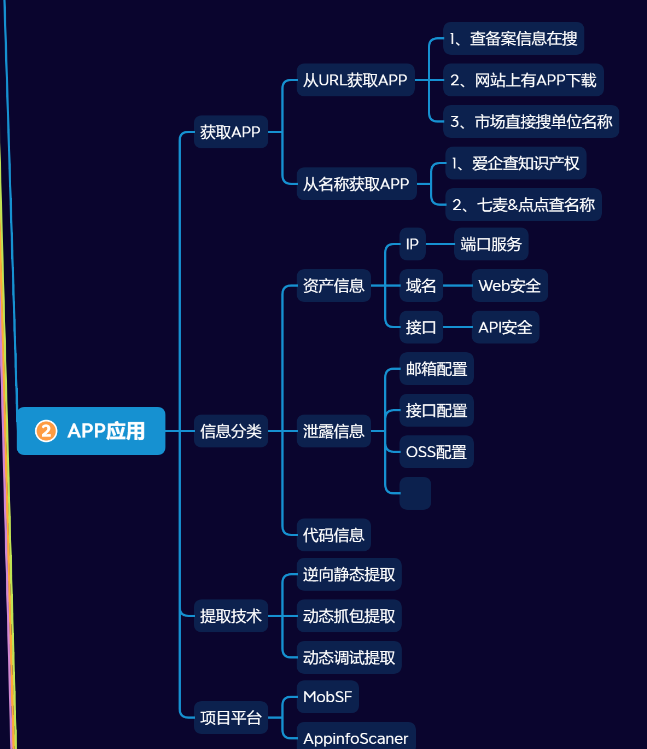
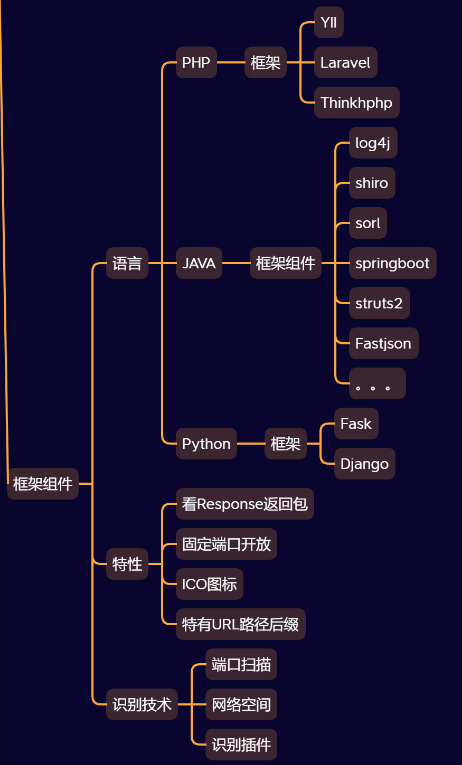
摘文笔记_常用技术一
- Log4j2使用以及异步性能 ,
- Springboot全局异常处理 ,
- Springboot自定义注解+拦截器实现敏感数据加解密 ,
- Docker图形化工具 ,
- SpringMVC:注解@ControllerAdvice的工作原理 ,
- 出路重复请求并转发 ,
- SpringAOP详解 ,
- java8 Stream流失编程.
Log4j2使用以及异步性能
Logback 算是JAVA 里一个老牌的日志框架,从06年开始第一个版本,迭代至今也十几年了。不过logback最近一个稳定版本还停留在 2017 年,好几年都没有更新;logback的兄弟 slf4j 最近一个稳定版也是2017年,有点凉凉的意思。
而且 logback的异步性能实在拉跨,功能简陋,配置又繁琐,远不及Apache 的新一代日志框架 - Log4j2
目前来看,Log4j2 就是王者,其他日志框架都不是对手
Log4j2简介
Apache Log4j 2是 Log4j(1) 的升级版,比它的祖先 Log4j 1. x 有了很大的改进,和logback对比有很大的改进。除了内部设计的调整外,主要有以下几点的大升级:
- 更简化的配置
- 更强大的参数格式化
- 最夸张的异步性能
Log4j 2中,分为API(log4j-api)和实现(log4j-core)两个模块。API 和slf4j 是一个类型,属于日志抽象/门面,而实现部分,才是Log4j 2的核心。
- org.apache.logging.log4j » log4j-api
- org.apache.logging.log4j » log4j-core
最牛逼的性能
最强的异步性能
这个特性,算是Log4j2最强之处了。log4j2 在目前JAVA中的日志框架里,异步日志的性能是最高的,没有之一。
先来看一下,几种日志框架benchmark对比结果(log4j2官方测试结果):

从图上可以看出,log4j2的异步(全异步,非混合模式)下的性能,远超log4j1和logback,简直吊打。压力越大的情况下,吞吐上的差距就越大。在64线程测试下,log4j2的吞吐达到了180w+/s,而logback/log4j1只有不到20w,相差近十倍
零GC(Garbage-free)
从2.6版本开始(2016年),log4j2 默认就以零GC模式运行了。什么叫零GC呢?就是不会由于log4j2而导致GC。
log4j2 中各种Message对象,字符串数组,字节数组等全部复用,不重复创建,大大减少了无用对象的创建,从而做到“零GC”。
更高性能 I/O 写入的支持
log4j 还提供了一个MemoryMappedFileAppender,I/O 部分使用MemoryMappedFile来实现,可以得到极高的I/O性能。不过在使用MemoryMappedFileAppender之前,得确定你足够了解MemoryMappedFile的相关知识,否则不要轻易使用呦。
更强大的参数格式化
API模块和slf4j相比,提供了更丰富的参数格式化功能。
使用{}占位符格式化参数
在slf4j里,我们可以用{}的方式来实现“format”的功能(参数会直接toString替换占位符),像下面这样:
1 | logger.debug("Logging in user {} with birthday {}", user.getName(), user.getBirthdayCalendar()); |
使用String.format的形式格式化参数
log4j2 中除了支持{}的参数占位符,还支持String.format的形式:
1 | public static Logger logger = LogManager.getFormatterLogger("Foo"); |
** 注意,如果想使用String.format的形式,需要使用LogManager.getFormatterLogger而不是LogManager.getLogger**
使用logger.printf格式化参数
log4j2 的 Logger接口中,还有一个printf方法,无需创建LogManager.getFormatterLogger,就可以使用String.format的形式
1 | logger.printf(Level.INFO, "Logging in user %1$s with birthday %2$tm %2$te,%2$tY", user.getName(), user.getBirthdayCalendar()); |
“惰性”打日志(lazy logging)
这个功能虽然小,但非常实用。
在某些业务流程里,为了留根或追溯问题,需要完整的打印入参,一般是把入参给用JSON/XML序列化后用debug级别打印:
1 | logger.debug("入参报文:{}",JSON.toJSONString(policyDTO)); |
如果需要追溯问题时,会将系统的日志级别调到debug/trace,这样就可以打印。但是这里有个问题,虽然在info级别下debug不会输出内容,但JSON.toJSONString()这个序列化的代码一定会执行,严重影响正常流程下的执行效率。
我们期望的结果是info级别下,连序列化都不执行。这里可以通过isDebugEnable来判断当前配置下debug级别是否可以输出:
1 | if(logger.isDebugEnabled()){ |
这样虽然可以避免不必要的序列化,但每个地方都这么写还是有点难受的,一行变成了三行。
log4j2 的 logger 对象,提供了一系列lambda的支持,通过这些接口可以实现“惰性”打日志:
1 | void debug(String message, Supplier<?>... paramSuppliers); |
这种 Supplier + Lambda 的形式,等同于上面的先判断 isDebugEnable 然后打印,三行的代码变成了一行。嗯,真香。
更简化的配置
Log4j 2 同时支持XML/JSON/YML/Properties 四种形式的配置文件,不过最主流的还是XML的方式,最直观。
来看一下logback和log4j2的配置文件对比,同样功能的配置下:
logback.xml
1 |
|
log4j2.xml
1 |
|
在log4j2中,appender的配置从使用 Appender 实现名即标签名的形式,语法上更简洁一些:
1 | <RollingFile name="File"> |
与其他日志抽象/门面适配
log4j2 由于拆分为 API 和 实现两部分,所以可能也需要和其他日志框架进行适配,详细的日志框架适配方案请参考我的另一篇文章《【可能是全网最全的】JAVA日志框架适配/冲突解决方案》
其他的特点
- 异步队列使用高性能队列 - **LMAX Disruptor **
- Appender丰富,有JMS/JPA/KAFKA/Http/MONGODB/CouchDB/Socket/Script等各种Appender的支持
- 支持自定义日志级别
- ……
基本用法
终于介绍完了Log4j2的强大,现在来介绍下Log4j2的基本使用。
引用log4j2的maven依赖
log4j-api在log4j-core中已经有依赖了,直接依赖core即可
1 | <dependency> |
注意,引用log4j2时,需要注意项目中是否有多套日志框架共存/冲突,需要适配的问题。细节请参考上面的与其他日志抽象/门面适配
配置文件示例
首先是配置文件,默认的配置文件路径为:classpath:log4j2.xml(推荐使用xml)
1 |
|
XML配置文件语法
1 | ; |
创建Logger
直接使用log4j2的api:
1 | import org.apache.logging.log4j.LogManager; |
如果是配合slf4j使用也是可以的,只需要按照前面说的,提前做好适配,然后使用slf4j的api即可。不过如果是新系统的话,建议直接上log4j2的api吧,可以享受所有log4j2的功能,使用slf4j之类的api时,上面说的参数格式化之类的功能就无法使用了。
全异步配置(重要!!)
推荐配置log4j2 全异步(all async),只需要在主程序代码开头,加一句系统属性的代码::
1 | System.setProperty("Log4jContextSelector", "org.apache.logging.log4j.core.async.AsyncLoggerContextSelector"); |
总结
Log4j2 如今性能最强,功能最强,而且持续更新维护。还在等什么?是时候替换你的logback/log4j1了!
SpringBoot 的全局异常处理
本篇文章主要介绍的是SpringBoot项目进行全局异常的处理。
SpringBoot全局异常准备
说明:如果想直接获取工程那么可以直接跳到底部,通过链接下载工程代码。
开发准备
环境要求
JDK:1.8
SpringBoot:1.5.17.RELEASE
首先还是Maven的相关依赖:
1 | <properties> |
配置文件这块基本不需要更改,全局异常的处理只需在代码中实现即可。
代码编写
SpringBoot的项目已经对有一定的异常处理了,但是对于我们开发者而言可能就不太合适了,因此我们需要对这些异常进行统一的捕获并处理。SpringBoot中有一个ControllerAdvice的注解,使用该注解表示开启了全局异常的捕获,我们只需在自定义一个方法使用ExceptionHandler注解然后定义捕获异常的类型即可对这些捕获的异常进行统一的处理。
我们根据下面的这个示例来看该注解是如何使用吧。
示例代码:
1 |
|
上述的示例中,我们对捕获的异常进行简单的二次处理,返回异常的信息,虽然这种能够让我们知道异常的原因,但是在很多的情况下来说,可能还是不够人性化,不符合我们的要求。那么我们这里可以通过自定义的异常类以及枚举类来实现我们想要的那种数据吧。
自定义基础接口类
首先定义一个基础的接口类,自定义的错误描述枚举类需实现该接口。代码如下:
1 | public interface BaseErrorInfoInterface { |
自定义枚举类
然后我们这里在自定义一个枚举类,并实现该接口。代码如下:
1 | public enum CommonEnum implements BaseErrorInfoInterface { |
自定义异常类
然后我们在来自定义一个异常类,用于处理我们发生的业务异常。代码如下:
1 | public class BizException extends RuntimeException { |
自定义数据格式
顺便这里我们定义一下数据的传输格式。代码如下:
1 | public class ResultBody { |
自定义全局异常处理类
最后我们在来编写一个自定义全局异常处理的类。代码如下:
1 |
|
因为这里我们只是用于做全局异常处理的功能实现以及测试,所以这里我们只需在添加一个实体类和一个控制层类即可。
实体类
又是万能的用户表 (▽)
代码如下:
1 | public class User implements Serializable{ |
Controller 控制层
控制层这边也比较简单,使用Restful风格实现的CRUD功能,不同的是这里我故意弄出了一些异常,好让这些异常被捕获到然后处理。这些异常中,有自定义的异常抛出,也有空指针的异常抛出,当然也有不可预知的异常抛出(这里我用类型转换异常代替),那么我们在完成代码编写之后,看看这些异常是否能够被捕获处理成功吧!
代码如下:
1 |
|
App 入口
和普通的SpringBoot项目基本一样。
代码如下:
1 |
|
功能测试
我们成功启动该程序之后,使用Postman工具来进行接口测试。
首先进行查询,查看程序正常运行是否ok,使用GET 方式进行请求。
1 | GET [http://localhost:8181/api/user](http://localhost:8181/api/user) |
返回参数为:
1 | {"id":1,"name":"xuwujing","age":18} |
示例图:
可以看到程序正常返回,并没有因自定义的全局异常而影响。
然后我们再来测试下自定义的异常是否能够被正确的捕获并处理。
使用POST方式进行请求
1 | POST [http://localhost:8181/api/user](http://localhost:8181/api/user) |
Body参数为:
1 | {"id":1,"age":18} |
返回参数为:
1 | {"code":"-1","message":"用户姓名不能为空!","result":null} |
示例图:

可以看出将我们抛出的异常进行数据封装,然后将异常返回出来。
然后我们再来测试下空指针异常是否能够被正确的捕获并处理。在自定义全局异常中,我们除了定义空指针的异常处理,也定义最高级别之一的Exception异常,那么这里发生了空指针异常之后,它是回优先使用哪一个呢?这里我们来测试下。
使用PUT方式进行请求。
1 | PUT [http://localhost:8181/api/user](http://localhost:8181/api/user) |
Body参数为:
1 | {"id":1,"age":18} |
返回参数为:
1 | {"code":"400","message":"请求的数据格式不符!","result":null} |
示例图:
我们可以看到这里的的确是返回空指针的异常护理,可以得出全局异常处理优先处理子类的异常。
那么我们在来试试未指定其异常的处理,看该异常是否能够被捕获。
使用DELETE方式进行请求。
1 | DELETE [http://localhost:8181/api/user](http://localhost:8181/api/user) |
Body参数为:
1 | {"id":1} |
返回参数为:
1 | {"code":"500","message":"服务器内部错误!","result":null} |

这里可以看到它使用了我们在自定义全局异常处理类中的Exception异常处理的方法。到这里,测试就结束了。顺便再说一下,自义定全局异常处理除了可以处理上述的数据格式之外,也可以处理页面的跳转,只需在新增的异常方法的返回处理上填写该跳转的路径并不使用ResponseBody 注解即可。细心的同学也许发现了在GlobalExceptionHandler类中使用的是ControllerAdvice注解,而非RestControllerAdvice注解,如果是用的RestControllerAdvice注解,它会将数据自动转换成JSON格式,这种于Controller和RestController类似,所以我们在使用全局异常处理的之后可以进行灵活的选择处理。
在SpringBoot项目中,自定义注解+拦截器优雅的实现敏感数据的加解密!
在实际生产项目中,经常需要对如身份证信息、手机号、真实姓名等的敏感数据进行加密数据库存储,但在业务代码中对敏感信息进行手动加解密则十分不优雅,甚至会存在错加密、漏加密、业务人员需要知道实际的加密规则等的情况。
本文将介绍使用springboot+mybatis拦截器+自定义注解的形式对敏感数据进行存储前拦截加密的详细过程。
一、什么是Mybatis Plugin
在mybatis官方文档中,对于Mybatis plugin的的介绍是这样的:
MyBatis 允许你在已映射语句执行过程中的某一点进行拦截调用。默认情况下,MyBatis 允许使用插件来拦截的方法调用包括:
1 | //语句执行拦截 |
简而言之,即在执行sql的整个周期中,我们可以任意切入到某一点对sql的参数、sql执行结果集、sql语句本身等进行切面处理。基于这个特性,我们便可以使用其对我们需要进行加密的数据进行切面统一加密处理了(分页插件 pageHelper 就是这样实现数据库分页查询的)。
二、实现基于注解的敏感信息加解密拦截器
2.1 实现思路
对于数据的加密与解密,应当存在两个拦截器对数据进行拦截操作
参照官方文档,因此此处我们应当使用ParameterHandler拦截器对入参进行加密
使用ResultSetHandler拦截器对出参进行解密操作。

目标需要加密、解密的字段可能需要灵活变更,此时我们定义一个注解,对需要加密的字段进行注解,那么便可以配合拦截器对需要的数据进行加密与解密操作了。
mybatis的interceptor接口有以下方法需要实现。
1 | public interface Interceptor { |
2.2 定义需要加密解密的敏感信息注解
定义注解敏感信息类(如实体类POJO\PO)的注解
1 | /** |
定义注解敏感信息类中敏感字段的注解
1 | /** |
2.3 定义加密接口及其实现类
定义加密接口,方便以后拓展加密方法(如AES加密算法拓展支持PBE算法,只需要注入时指定一下便可)
1 | public interface EncryptUtil { |
EncryptUtil 的AES加密实现类,此处AESUtil为自封装的AES加密工具,需要的小伙伴可以自行封装,本文不提供。(搜索公众号Java知音,回复“2021”,送你一份Java面试题宝典)
1 |
|
2.4 实现入参加密拦截器
Myabtis包中的org.apache.ibatis.plugin.Interceptor拦截器接口要求我们实现以下三个方法
1 | public interface Interceptor { |
因此,参考官方文档的示例,我们自定义一个入参加密拦截器。
@Intercepts 注解开启拦截器,@Signature 注解定义拦截器的实际类型。
@Signature中
- type 属性指定当前拦截器使用StatementHandler 、ResultSetHandler、ParameterHandler,Executor的一种
- method 属性指定使用以上四种类型的具体方法(可进入class内部查看其方法)。
- args 属性指定预编译语句
此处我们使用了 ParameterHandler.setParamters()方法,拦截mapper.xml中paramsType的实例(即在每个含有paramsType属性mapper语句中,都执行该拦截器,对paramsType的实例进行拦截处理)
1 | /** |
至此完成自定义加密拦截加密。
2.5 定义解密接口及其实现类
解密接口,其中result为mapper.xml中resultType的实例。
1 | public interface DecryptUtil { |
解密接口AES工具解密实现类
1 | public class AESDecrypt implements DecryptUtil { |
2.6 定义出参解密拦截器
1 |
|
至此完成解密拦截器的配置工作。
3、注解实体类中需要加解密的字段

此时在mapper中,指定paramType=User resultType=User 便可实现脱离业务层,基于mybatis拦截器的加解密操作。
Docker 图形化工具:Portainer
一.Docker图形化工具
docker 图形页面管理工具常用的有三种,DockerUI ,Portainer ,Shipyard 。DockerUI 是 Portainer 的前身,这三个工具通过docker api来获取管理的资源信息。
平时我们常常对着shell对着这些命令行客户端,审美会很疲劳,如果有漂亮的图形化界面可以直观查看docker资源信息,也是非常方便的。
今天我们就搭建单机版的三种常用图形页面管理工具。这三种图形化管理工具以Portainer最为受欢迎。
二.DockerUI
轻量级图形页面管理之DockerUI
1.查看dockerui镜像
1 | [root@localhost ~]# docker search dockerui |
2.选择喜欢的dockerui风格镜像,下载
1 | [root@localhost ~]# docker pull abh1nav/dockerui |
3.启动dockerui容器,这里需要注意带上privileged参数,提升权限
1 | [root@localhost ~]# docker run -d --privileged --name dockerui -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock abh1nav/dockerui |
前往网页查看之前,你需要打开服务器的9000端口: firewall-cmd –permanent –zone=public –add-port=9000/tcpfirewall-cmd –reload
4.浏览器查看dockerui:http://192.168.2.119:9000 或者 curl http://192.168.2.119:9000

三.Shipyard
轻量级图形页面管理之Shipyard

四.Portainer
轻量级图形页面管理之Portainer
1.查看portainer镜像
1 | [root@localhost ~]# docker search portainer |
2.选择喜欢的portainer风格镜像,下载
1 | docker pull portainer/portainer |
3.启动dockerui容器
1 | docker volume create portainer_data |
参数说明:
-v /var/run/docker.sock:/var/run/docker.sock:把宿主机的Docker守护进程(Docker daemon)默认监听的Unix域套接字挂载到容器中;-v portainer\_data:/data:把宿主机portainer_data数据卷挂载到容器/data目录;
4.web管理
1、登陆 http://x.x.x.x:9000,设置管理员账号和密码。
2、单机版在新页面选择 Local 即可完成安装,集群选择Remote然后输入SWARM的IP地址,点击Connect完成安装。
浏览器访问 http://192.168.2.119:9000 , 设置一个密码即可,点击创建用户


我们搭建的是单机版,直接选择Local ,点击连接


现在就可以使用了,点击Local进入仪表盘主页面。

容器页面

SpringMVC:注解@ControllerAdvice的工作原理
Spring MVC中,通过组合使用注解@ControllerAdvice和其他一些注解,我们可以为开发人员实现的控制器类做一些全局性的定制,具体来讲,可作如下定制 :
结合
@ExceptionHandler使用 ==> 添加统一的异常处理控制器方法结合
@ModelAttribute使用 ==> 使用共用方法添加渲染视图的数据模型属性结合
@InitBinder使用 ==> 使用共用方法初始化控制器方法调用使用的数据绑定器数据绑定器涉及到哪些参数/属性需要/不需要绑定,设置数据类型转换时使用的
PropertyEditor,Formatter等。
那么,@ControllerAdvice的工作原理又是怎样的呢 ?这篇文章,我们就一探究竟。
1. 注解@ControllerAdvice是如何被发现的 ?
首先,容器启动时,会定义类型为RequestMappingHandlerAdapter的bean组件,这是DispatcherServlet用于执行控制器方法的HandlerAdapter,它实现了接口InitializingBean,所以自身在初始化时其方法#afterPropertiesSet会被调用执行。
1 |
|
从以上代码可以看出,RequestMappingHandlerAdapter bean组件在自身初始化时调用了#initControllerAdviceCache,从这个方法的名字上就可以看出,这是一个ControllerAdvice相关的初始化函数,而#initControllerAdviceCache具体又做了什么呢?我们继续来看 :
1 | private void initControllerAdviceCache() { |
从以上#initControllerAdviceCache方法的实现逻辑来看,它将容器中所有使用了注解@ControllerAdvice的bean或者其方法都分门别类做了统计,记录到了RequestMappingHandlerAdapter实例的三个属性中 :
requestResponseBodyAdvice- 用于记录所有
@ControllerAdvice+RequestBodyAdvice/ResponseBodyAdvicebean组件 modelAttributeAdviceCache- 用于记录所有
@ControllerAdvicebean组件中的@ModuleAttribute方法 initBinderAdviceCache- 用于记录所有
@ControllerAdvicebean组件中的@InitBinder方法
到此为止,我们知道,使用注解@ControllerAdvice的bean中的信息被提取出来了,但是,这些信息又是怎么使用的呢 ?我们继续来看。
2. @ControllerAdvice 定义信息的使用
1. requestResponseBodyAdvice的使用
1 | /** |
#getDefaultArgumentResolvers方法用于准备RequestMappingHandlerAdapter执行控制器方法过程中缺省使用的HandlerMethodArgumentResolver,从上面代码可见,requestResponseBodyAdvice会被传递给RequestResponseBodyMethodProcessor/RequestPartMethodArgumentResolver/HttpEntityMethodProcessor这三个参数解析器,不难猜测,它们在工作时会使用到该requestResponseBodyAdvice,但具体怎么使用,为避免过深细节影响理解,本文我们不继续展开。
方法#getDefaultArgumentResolvers也在RequestMappingHandlerAdapter初始化方法中被调用执行,如下所示 :
1 |
|
2. modelAttributeAdviceCache的使用
1 | private ModelFactory getModelFactory(HandlerMethod handlerMethod, WebDataBinderFactory binderFactory) { |
从此方法可以看到,#getModelFactory方法使用到了modelAttributeAdviceCache,它会根据其中每个元素构造成一个InvocableHandlerMethod,最终传递给要创建的ModelFactory对象。而#getModelFactory又在什么时候被使用呢 ? 它会在RequestMappingHandlerAdapter执行一个控制器方法的准备过程中被调用,如下所示 :
1 |
|
3. initBinderAdviceCache的使用
1 | private WebDataBinderFactory getDataBinderFactory(HandlerMethod handlerMethod) throws Exception { |
从此方法可以看到,#getDataBinderFactory方法使用到了initBinderAdviceCache,它会根据其中每个元素构造成一个InvocableHandlerMethod,最终传递给要创建的InitBinderDataBinderFactory对象。而#getDataBinderFactory又在什么时候被使用呢 ? 它会在RequestMappingHandlerAdapter执行一个控制器方法的准备过程中被调用,如下所示 :
1 |
|
到此为止,我们基本上可以看到,通过@ControllerAdvice注解的bean组件所定义的@ModelAttribute/@InitBinder方法,或者RequestBodyAdvice/ResponseBodyAdvice,是如何被RequestMappingHandlerAdapter提取和使用的了。虽然我们并未深入到更细微的组件研究它们最终的使用,不过结合这些组件命名以及这些更深一层的使用者组件的名称,即便是猜测,相信你也不难理解猜到它们如何被使用了。
不知道你注意到没有,关于@ControllerAdvice和@ExceptionHandler这一组合,在上面提到的RequestMappingHandlerAdapter逻辑中,并未涉及到。那如果使用了这种组合,又会是怎样一种工作机制呢 ?事实上,@ControllerAdvice和@ExceptionHandler这一组合所做的定义,会被ExceptionHandlerExceptionResolver消费使用。不过关于ExceptionHandlerExceptionResolver我们会另外行文介绍,通过这篇文章中的例子,理解@ControllerAdvide的工作原理已经不是问题了。
如何优雅处理重复请求/并发请求?
对于一些用户请求,在某些情况下是可能重复发送的,如果是查询类操作并无大碍,但其中有些是涉及写入操作的,一旦重复了,可能会导致很严重的后果,例如交易的接口如果重复请求可能会重复下单。
重复的场景有可能是:
- 黑客拦截了请求,重放
- 前端/客户端因为某些原因请求重复发送了,或者用户在很短的时间内重复点击了。
- 网关重发
- ….
本文讨论的是如何在服务端优雅地统一处理这种情况,如何禁止用户重复点击等客户端操作不在本文的讨论范畴。
利用唯一请求编号去重
你可能会想到的是,只要请求有唯一的请求编号,那么就能借用Redis做这个去重——只要这个唯一请求编号在redis存在,证明处理过,那么就认为是重复的
代码大概如下:
1 | String KEY = "REQ12343456788";//请求唯一编号 |
业务参数去重
上面的方案能解决具备唯一请求编号的场景,例如每次写请求之前都是服务端返回一个唯一编号给客户端,客户端带着这个请求号做请求,服务端即可完成去重拦截。
但是,很多的场景下,请求并不会带这样的唯一编号!那么我们能否针对请求的参数作为一个请求的标识呢?
先考虑简单的场景,假设请求参数只有一个字段reqParam,我们可以利用以下标识去判断这个请求是否重复。用户ID:接口名:请求参数
1 | String KEY = "dedup:U="+userId + "M=" + method + "P=" + reqParam; |
那么当同一个用户访问同一个接口,带着同样的reqParam过来,我们就能定位到他是重复的了。
但是问题是,我们的接口通常不是这么简单,以目前的主流,我们的参数通常是一个JSON。那么针对这种场景,我们怎么去重呢?
计算请求参数的摘要作为参数标识
假设我们把请求参数(JSON)按KEY做升序排序,排序后拼成一个字符串,作为KEY值呢?但这可能非常的长,所以我们可以考虑对这个字符串求一个MD5作为参数的摘要,以这个摘要去取代reqParam的位置。
1 | String KEY = "dedup:U="+userId + "M=" + method + "P=" + reqParamMD5; |
这样,请求的唯一标识就打上了!
注:MD5理论上可能会重复,但是去重通常是短时间窗口内的去重(例如一秒),一个短时间内同一个用户同样的接口能拼出不同的参数导致一样的MD5几乎是不可能的。
继续优化,考虑剔除部分时间因子
上面的问题其实已经是一个很不错的解决方案了,但是实际投入使用的时候可能发现有些问题:某些请求用户短时间内重复的点击了(例如1000毫秒发送了三次请求),但绕过了上面的去重判断(不同的KEY值)。
原因是这些请求参数的字段里面,是带时间字段的,这个字段标记用户请求的时间,服务端可以借此丢弃掉一些老的请求(例如5秒前)。如下面的例子,请求的其他参数是一样的,除了请求时间相差了一秒:
1 | //两个请求一样,但是请求时间差一秒 |
这种请求,我们也很可能需要挡住后面的重复请求。所以求业务参数摘要之前,需要剔除这类时间字段。还有类似的字段可能是GPS的经纬度字段(重复请求间可能有极小的差别)。
请求去重工具类,Java实现
1 | public class ReqDedupHelper { |
下面是一些测试日志:
1 | public static void main(String[] args) { |
日志输出:
1 | req1MD5 = 9E054D36439EBDD0604C5E65EB5C8267 , req2MD5=A2D20BAC78551C4CA09BEF97FE468A3F |
日志说明:
- 一开始两个参数由于requestTime是不同的,所以求去重参数摘要的时候可以发现两个值是不一样的
- 第二次调用的时候,去除了requestTime再求摘要(第二个参数中传入了”requestTime”),则发现两个摘要是一样的,符合预期。
总结
至此,我们可以得到完整的去重解决方案,如下:
1 | String userId= "12345678";//用户 |
Spring AOP看这篇就够辣~
基本知识
其实, 接触了这么久的 AOP, 我感觉, AOP 给人难以理解的一个关键点是它的概念比较多, 而且坑爹的是, 这些概念经过了中文翻译后, 变得面目全非, 相同的一个术语, 在不同的翻译下, 含义总有着各种莫名其妙的差别. 鉴于此, 我在本章的开头, 着重为为大家介绍一个 Spring AOP 的各项术语的基本含义. 为了术语传达的准确性, 我在接下来的叙述中, 能使用英文术语的地方, 尽量使用英文.
什么是 AOP
AOP(Aspect-Oriented Programming), 即 面向切面编程 , 它与 OOP( Object-Oriented Programming, 面向对象编程) 相辅相成, 提供了与 OOP 不同的抽象软件结构的视角. 在 OOP 中, 我们以类(class)作为我们的基本单元, 而 AOP 中的基本单元是 Aspect(切面)
术语
Aspect(切面)
aspect 由 pointcount 和 advice 组成, 它既包含了横切逻辑的定义, 也包括了连接点的定义. Spring AOP就是负责实施切面的框架, 它将切面所定义的横切逻辑织入到切面所指定的连接点中. AOP的工作重心在于如何将增强织入目标对象的连接点上, 这里包含两个工作:
- 如何通过 pointcut 和 advice 定位到特定的 joinpoint 上
- 如何在 advice 中编写切面代码.
可以简单地认为, 使用 @Aspect 注解的类就是切面.
advice(增强)
由 aspect 添加到特定的 join point(即满足 point cut 规则的 join point) 的一段代码. 许多 AOP框架, 包括 Spring AOP, 会将 advice 模拟为一个拦截器(interceptor), 并且在 join point 上维护多个 advice, 进行层层拦截. 例如 HTTP 鉴权的实现, 我们可以为每个使用 RequestMapping 标注的方法织入 advice, 当 HTTP 请求到来时, 首先进入到 advice 代码中, 在这里我们可以分析这个 HTTP 请求是否有相应的权限, 如果有, 则执行 Controller, 如果没有, 则抛出异常. 这里的 advice 就扮演着鉴权拦截器的角色了.
连接点(join point)
a point during the execution of a program, such as the execution of a method or the handling of an exception. In Spring AOP, a join point always represents a method execution.
程序运行中的一些时间点, 例如一个方法的执行, 或者是一个异常的处理.在 Spring AOP 中, join point 总是方法的执行点, 即只有方法连接点.
切点(point cut)
匹配 join point 的谓词(a predicate that matches join points). Advice 是和特定的 point cut 关联的, 并且在 point cut 相匹配的 join point 中执行.在 Spring 中, 所有的方法都可以认为是 joinpoint, 但是我们并不希望在所有的方法上都添加 Advice, 而 pointcut 的作用就是提供一组规则(使用 AspectJ pointcut expression language 来描述) 来匹配joinpoint, 给满足规则的 joinpoint 添加 Advice.
关于join point 和 point cut 的区别
在 Spring AOP 中, 所有的方法执行都是 join point. 而 point cut 是一个描述信息, 它修饰的是 join point, 通过 point cut, 我们就可以确定哪些 join point 可以被织入 Advice. 因此 join point 和 point cut 本质上就是两个不同纬度上的东西.advice 是在 join point 上执行的, 而 point cut 规定了哪些 join point 可以执行哪些 advice
introduction
为一个类型添加额外的方法或字段. Spring AOP 允许我们为 目标对象 引入新的接口(和对应的实现). 例如我们可以使用 introduction 来为一个 bean 实现 IsModified 接口, 并以此来简化 caching 的实现.
目标对象(Target)
织入 advice 的目标对象. 目标对象也被称为 advised object.因为 Spring AOP 使用运行时代理的方式来实现 aspect, 因此 adviced object 总是一个代理对象(proxied object)``注意, adviced object 指的不是原来的类, 而是织入 advice 后所产生的代理类.
AOP proxy
一个类被 AOP 织入 advice, 就会产生一个结果类, 它是融合了原类和增强逻辑的代理类. 在 Spring AOP 中, 一个 AOP 代理是一个 JDK 动态代理对象或 CGLIB 代理对象.
织入(Weaving)
将 aspect 和其他对象连接起来, 并创建 adviced object 的过程. 根据不同的实现技术, AOP织入有三种方式:
- 编译器织入, 这要求有特殊的Java编译器.
- 类装载期织入, 这需要有特殊的类装载器.
- 动态代理织入, 在运行期为目标类添加增强(Advice)生成子类的方式. Spring 采用动态代理织入, 而AspectJ采用编译器织入和类装载期织入.
advice 的类型
- before advice, 在 join point 前被执行的 advice. 虽然 before advice 是在 join point 前被执行, 但是它并不能够阻止 join point 的执行, 除非发生了异常(即我们在 before advice 代码中, 不能人为地决定是否继续执行 join point 中的代码)
- after return advice, 在一个 join point 正常返回后执行的 advice
- after throwing advice, 当一个 join point 抛出异常后执行的 advice
- after(final) advice, 无论一个 join point 是正常退出还是发生了异常, 都会被执行的 advice.
- around advice, 在 join point 前和 joint point 退出后都执行的 advice. 这个是最常用的 advice.
关于 AOP Proxy
Spring AOP 默认使用标准的 JDK 动态代理(dynamic proxy)技术来实现 AOP 代理, 通过它, 我们可以为任意的接口实现代理.如果需要为一个类实现代理, 那么可以使用 CGLIB 代理. 当一个业务逻辑对象没有实现接口时, 那么Spring AOP 就默认使用 CGLIB 来作为 AOP 代理了. 即如果我们需要为一个方法织入 advice, 但是这个方法不是一个接口所提供的方法, 则此时 Spring AOP 会使用 CGLIB 来实现动态代理. 鉴于此, Spring AOP 建议基于接口编程, 对接口进行 AOP 而不是类.
彻底理解 aspect, join point, point cut, advice
看完了上面的理论部分知识, 我相信还是会有不少朋友感觉到 AOP 的概念还是很模糊, 对 AOP 中的各种概念理解的还不是很透彻. 其实这很正常, 因为 AOP 中的概念是在是太多了, 我当时也是花了老大劲才梳理清楚的. 下面我以一个简单的例子来比喻一下 AOP 中 aspect, jointpoint, pointcut 与 advice 之间的关系.
让我们来假设一下, 从前有一个叫爪哇的小县城, 在一个月黑风高的晚上, 这个县城中发生了命案. 作案的凶手十分狡猾, 现场没有留下什么有价值的线索. 不过万幸的是, 刚从隔壁回来的老王恰好在这时候无意中发现了凶手行凶的过程, 但是由于天色已晚, 加上凶手蒙着面, 老王并没有看清凶手的面目, 只知道凶手是个男性, 身高约七尺五寸. 爪哇县的县令根据老王的描述, 对守门的士兵下命令说: 凡是发现有身高七尺五寸的男性, 都要抓过来审问. 士兵当然不敢违背县令的命令, 只好把进出城的所有符合条件的人都抓了起来.
来让我们看一下上面的一个小故事和 AOP 到底有什么对应关系. 首先我们知道, 在 Spring AOP 中 join point 指代的是所有方法的执行点, 而 point cut 是一个描述信息, 它修饰的是 join point, 通过 point cut, 我们就可以确定哪些 join point 可以被织入 Advice. 对应到我们在上面举的例子, 我们可以做一个简单的类比, join point 就相当于 爪哇的小县城里的百姓 , point cut 就相当于 老王所做的指控, 即凶手是个男性, 身高约七尺五寸 , 而 advice 则是施加在符合老王所描述的嫌疑人的动作: 抓过来审问 . 为什么可以这样类比呢?
- join point –> 爪哇的小县城里的百姓: 因为根据定义, join point 是所有可能被织入 advice 的候选的点, 在 Spring AOP中, 则可以认为所有方法执行点都是 join point. 而在我们上面的例子中, 命案发生在小县城中, 按理说在此县城中的所有人都有可能是嫌疑人.
- point cut –> 男性, 身高约七尺五寸: 我们知道, 所有的方法(joint point) 都可以织入 advice, 但是我们并不希望在所有方法上都织入 advice, 而 pointcut 的作用就是提供一组规则来匹配joinpoint, 给满足规则的 joinpoint 添加 advice. 同理, 对于县令来说, 他再昏庸, 也知道不能把县城中的所有百姓都抓起来审问, 而是根据
凶手是个男性, 身高约七尺五寸, 把符合条件的人抓起来. 在这里凶手是个男性, 身高约七尺五寸就是一个修饰谓语, 它限定了凶手的范围, 满足此修饰规则的百姓都是嫌疑人, 都需要抓起来审问. - advice –> 抓过来审问, advice 是一个动作, 即一段 Java 代码, 这段 Java 代码是作用于 point cut 所限定的那些 join point 上的. 同理, 对比到我们的例子中,
抓过来审问这个动作就是对作用于那些满足男性, 身高约七尺五寸的爪哇的小县城里的百姓. - aspect: aspect 是 point cut 与 advice 的组合, 因此在这里我们就可以类比: “根据老王的线索, 凡是发现有身高七尺五寸的男性, 都要抓过来审问” 这一整个动作可以被认为是一个 aspect.
或则我们也可以从语法的角度来简单类比一下. 我们在学英语时, 经常会接触什么 定语, 被动句 之类的概念, 那么可以做一个不严谨的类比, 即 joinpoint 可以认为是一个 宾语, 而 pointcut 则可以类比为修饰 joinpoint 的定语, 那么整个 aspect 就可以描述为: 满足 pointcut 规则的 joinpoint 会被添加相应的 advice 操作.
@AspectJ 支持
@AspectJ 是一种使用 Java 注解来实现 AOP 的编码风格. @AspectJ 风格的 AOP 是 AspectJ Project 在 AspectJ 5 中引入的, 并且 Spring 也支持@AspectJ 的 AOP 风格.
使能 @AspectJ 支持
@AspectJ 可以以 XML 的方式或以注解的方式来使能, 并且不论以哪种方式使能@ASpectJ, 我们都必须保证 aspectjweaver.jar 在 classpath 中.
使用 Java Configuration 方式使能@AspectJ
1 |
|
使用 XML 方式使能@AspectJ
1 | <aop:aspectj-autoproxy/> |
定义 aspect(切面)
当使用注解 @Aspect 标注一个 Bean 后, 那么 Spring 框架会自动收集这些 Bean, 并添加到 Spring AOP 中, 例如:
1 |
|
声明 pointcut
一个 pointcut 的声明由两部分组成:
- 一个方法签名, 包括方法名和相关参数
- 一个 pointcut 表达式, 用来指定哪些方法执行是我们感兴趣的(即因此可以织入 advice).
在@AspectJ 风格的 AOP 中, 我们使用一个方法来描述 pointcut, 即:
1 | // 切点表达式 |
这个方法必须无返回值.``这个方法本身就是 pointcut signature, pointcut 表达式使用@Pointcut 注解指定.上面我们简单地定义了一个 pointcut, 这个 pointcut 所描述的是: 匹配所有在包 com.xys.service.UserService 下的所有方法的执行.
切点标志符(designator)
AspectJ5 的切点表达式由标志符(designator)和操作参数组成. 如 “execution( greetTo(..))” 的切点表达式, execution 就是 标志符, 而圆括号里的 greetTo(..) 就是操作参数
execution
匹配 join point 的执行, 例如 “execution(* hello(..))” 表示匹配所有目标类中的 hello() 方法. 这个是最基本的 pointcut 标志符.
within
匹配特定包下的所有 join point, 例如 within(com.xys.*) 表示 com.xys 包中的所有连接点, 即包中的所有类的所有方法. 而 within(com.xys.service.*Service) 表示在 com.xys.service 包中所有以 Service 结尾的类的所有的连接点.
this 与 target
this 的作用是匹配一个 bean, 这个 bean(Spring AOP proxy) 是一个给定类型的实例(instance of). 而 target 匹配的是一个目标对象(target object, 即需要织入 advice 的原始的类), 此对象是一个给定类型的实例(instance of).
bean
匹配 bean 名字为指定值的 bean 下的所有方法, 例如:
1 | bean(*Service) // 匹配名字后缀为 Service 的 bean 下的所有方法 |
args
匹配参数满足要求的的方法. 例如:
1 |
|
当 NormalService.test 执行时, 则 advice doSomething 就会执行, test 方法的参数 name 就会传递到 doSomething 中.
常用例子:
1 | // 匹配只有一个参数 name 的方法 |
@annotation
匹配由指定注解所标注的方法, 例如:
1 |
|
则匹配由注解 AuthChecker 所标注的方法.
常见的切点表达式
匹配方法签名
1 | // 匹配指定包中的所有的方法 |
匹配类型签名
1 | // 匹配指定包中的所有的方法, 但不包括子包 |
匹配 Bean 名字
1 | // 匹配以指定名字结尾的 Bean 中的所有方法 |
切点表达式组合
1 | // 匹配以 Service 或 ServiceImpl 结尾的 bean |
声明 advice
advice 是和一个 pointcut 表达式关联在一起的, 并且会在匹配的 join point 的方法执行的前/后/周围 运行. pointcut 表达式可以是简单的一个 pointcut 名字的引用, 或者是完整的 pointcut 表达式. 下面我们以几个简单的 advice 为例子, 来看一下一个 advice 是如何声明的.
Before advice
1 | /** |
这里, @Before 引用了一个 pointcut, 即 “com.xys.aspect.PointcutDefine.dataAccessOperation()” 是一个 pointcut 的名字. 如果我们在 advice 在内置 pointcut, 则可以:
1 |
|
around advice
around advice 比较特别, 它可以在一个方法的之前之前和之后添加不同的操作, 并且甚至可以决定何时, 如何, 是否调用匹配到的方法.
1 |
|
around advice 和前面的 before advice 差不多, 只是我们把注解 @Before 改为了 @Around 了.
Java8 Stream 流式编程,极大解放你的生产力!
[Java专注于Java领域干货分享,不限于BAT面试, 算法,数
Stream 流可以说是 Java8 新特性中用起来最爽的一个功能了,有了它,从此操作集合告别繁琐的 for 循环。但是还有很多小伙伴对 Stream 流不是很了解。今天就通过这篇 @Winterbe 的译文,一起深入了解下如何使用它吧。
目录
一、Stream 流是如何工作的?
二、不同类型的 Stream 流
三、Stream 流的处理顺序
四、中间操作顺序这么重要?
五、数据流复用问题
六、高级操作
- 6.1 Collect
- 6.2 FlatMap
- 6.3 Reduce
七、并行流
八、结语
当我第一次阅读 Java8 中的 Stream API 时,说实话,我非常困惑,因为它的名字听起来与 Java I0 框架中的 InputStream 和 OutputStream 非常类似。但是实际上,它们完全是不同的东西。
Java8 Stream 使用的是函数式编程模式,如同它的名字一样,它可以被用来对集合进行链状流式的操作。
本文就将带着你如何使用 Java 8 不同类型的 Stream 操作。同时您还将了解流的处理顺序,以及不同顺序的流操作是如何影响运行时性能的。
我们还将学习终端操作 API reduce, collect 以及 flatMap的详细介绍,最后我们再来深入的探讨一下 Java8 并行流。
注意:如果您还不熟悉 Java 8 lambda 表达式,函数式接口以及方法引用,您可以先阅读一下小哈的另一篇译文 《干货 | Java8 新特性指导手册》
接下来,就让我们进入正题吧!
一、Stream 流是如何工作的?
流表示包含着一系列元素的集合,我们可以对其做不同类型的操作,用来对这些元素执行计算。听上去可能有点拗口,让我们用代码说话:
1 | List<String> myList = Arrays.asList("a1", "a2", "b1", "c2", "c1"); |
我们可以对流进行中间操作或者终端操作。小伙伴们可能会疑问?什么是中间操作?什么又是终端操作?
- ①:中间操作会再次返回一个流,所以,我们可以链接多个中间操作,注意这里是不用加分号的。上图中的
filter过滤,map对象转换,sorted排序,就属于中间操作。 - ②:终端操作是对流操作的一个结束动作,一般返回
void或者一个非流的结果。上图中的forEach循环 就是一个终止操作。
看完上面的操作,感觉是不是很像一个流水线式操作呢。
实际上,大部分流操作都支持 lambda 表达式作为参数,正确理解,应该说是接受一个函数式接口的实现作为参数。
二、不同类型的 Stream 流
我们可以从各种数据源中创建 Stream 流,其中以 Collection 集合最为常见。如 List 和 Set 均支持 stream() 方法来创建顺序流或者是并行流。
并行流是通过多线程的方式来执行的,它能够充分发挥多核 CPU 的优势来提升性能。本文在最后再来介绍并行流,我们先讨论顺序流:
1 | Arrays.asList("a1", "a2", "a3") .stream() // 创建流 .findFirst() // 找到第一个元素 .ifPresent(System.out::println); // 如果存在,即输出 |
在集合上调用 stream()方法会返回一个普通的 Stream 流。但是, 您大可不必刻意地创建一个集合,再通过集合来获取 Stream 流,您还可以通过如下这种方式:
1 | Stream.of("a1", "a2", "a3") .findFirst() .ifPresent(System.out::println); // a1 |
例如上面这样,我们可以通过 Stream.of() 从一堆对象中创建 Stream 流。
除了常规对象流之外,Java 8还附带了一些特殊类型的流,用于处理原始数据类型 int, long以及 double。说道这里,你可能已经猜到了它们就是 IntStream, LongStream还有 DoubleStream。
其中, IntStreams.range()方法还可以被用来取代常规的 for 循环, 如下所示:
1 | IntStream.range(1, 4) .forEach(System.out::println); // 相当于 for (int i = 1; i < 4; i++) {} |
上面这些原始类型流的工作方式与常规对象流基本是一样的,但还是略微存在一些区别:
- 原始类型流使用其独有的函数式接口,例如
IntFunction代替Function,IntPredicate代替Predicate。 - 原始类型流支持额外的终端聚合操作,
sum()以及average(),如下所示:
1 | Arrays.stream(new int[] {1, 2, 3}) .map(n -> 2 * n + 1) // 对数值中的每个对象执行 2*n + 1 操作 .average() // 求平均值 .ifPresent(System.out::println); // 如果值不为空,则输出// 5.0 |
但是,偶尔我们也有这种需求,需要将常规对象流转换为原始类型流,这个时候,中间操作 mapToInt(), mapToLong() 以及 mapToDouble就派上用场了:
1 | Stream.of("a1", "a2", "a3") .map(s -> s.substring(1)) // 对每个字符串元素从下标1位置开始截取 .mapToInt(Integer::parseInt) // 转成 int 基础类型类型流 .max() // 取最大值 .ifPresent(System.out::println); // 不为空则输出 |
如果说,您需要将原始类型流装换成对象流,您可以使用 mapToObj()来达到目的:
1 | IntStream.range(1, 4) .mapToObj(i -> "a" + i) // for 循环 1->4, 拼接前缀 a .forEach(System.out::println); // for 循环打印 |
下面是一个组合示例,我们将双精度流首先转换成 int 类型流,然后再将其装换成对象流:
1 | Stream.of(1.0, 2.0, 3.0) .mapToInt(Double::intValue) // double 类型转 int .mapToObj(i -> "a" + i) // 对值拼接前缀 a .forEach(System.out::println); // for 循环打印 |
三、Stream 流的处理顺序
上小节中,我们已经学会了如何创建不同类型的 Stream 流,接下来我们再深入了解下数据流的执行顺序。
在讨论处理顺序之前,您需要明确一点,那就是中间操作的有个重要特性 —— 延迟性。观察下面这个没有终端操作的示例代码:
1 | Stream.of("d2", "a2", "b1", "b3", "c") .filter(s -> { System.out.println("filter: " + s); return true; }); |
执行此代码段时,您可能会认为,将依次打印 “d2”, “a2”, “b1”, “b3”, “c” 元素。然而当你实际去执行的时候,它不会打印任何内容。
为什么呢?
原因是:当且仅当存在终端操作时,中间操作操作才会被执行。
是不是不信?接下来,对上面的代码添加 forEach终端操作:
1 | Stream.of("d2", "a2", "b1", "b3", "c") .filter(s -> { System.out.println("filter: " + s); return true; }) .forEach(s -> System.out.println("forEach: " + s)); |
再次执行,我们会看到输出如下:
1 | filter: d2forEach: d2filter: a2forEach: a2filter: b1forEach: b1filter: b3forEach: b3filter: cforEach: c |
输出的顺序可能会让你很惊讶!你脑海里肯定会想,应该是先将所有 filter 前缀的字符串打印出来,接着才会打印 forEach 前缀的字符串。
事实上,输出的结果却是随着链条垂直移动的。比如说,当 Stream 开始处理 d2 元素时,它实际上会在执行完 filter 操作后,再执行 forEach 操作,接着才会处理第二个元素。
是不是很神奇?为什么要设计成这样呢?
原因是出于性能的考虑。这样设计可以减少对每个元素的实际操作数,看完下面代码你就明白了:
1 | Stream.of("d2", "a2", "b1", "b3", "c") .map(s -> { System.out.println("map: " + s); return s.toUpperCase(); // 转大写 }) .anyMatch(s -> { System.out.println("anyMatch: " + s); return s.startsWith("A"); // 过滤出以 A 为前缀的元素 }); |
终端操作 anyMatch()表示任何一个元素以 A 为前缀,返回为 true,就停止循环。所以它会从 d2 开始匹配,接着循环到 a2 的时候,返回为 true ,于是停止循环。
由于数据流的链式调用是垂直执行的, map这里只需要执行两次。相对于水平执行来说, map会执行尽可能少的次数,而不是把所有元素都 map 转换一遍。
四、中间操作顺序这么重要?
下面的例子由两个中间操作 map和 filter,以及一个终端操作 forEach组成。让我们再来看看这些操作是如何执行的:
1 | Stream.of("d2", "a2", "b1", "b3", "c") .map(s -> { System.out.println("map: " + s); return s.toUpperCase(); // 转大写 }) .filter(s -> { System.out.println("filter: " + s); return s.startsWith("A"); // 过滤出以 A 为前缀的元素 }) .forEach(s -> System.out.println("forEach: " + s)); // for 循环输出 |
学习了上面一小节,您应该已经知道了, map和 filter会对集合中的每个字符串调用五次,而 forEach却只会调用一次,因为只有 “a2” 满足过滤条件。
如果我们改变中间操作的顺序,将 filter移动到链头的最开始,就可以大大减少实际的执行次数:
1 | Stream.of("d2", "a2", "b1", "b3", "c") .filter(s -> { System.out.println("filter: " + s) return s.startsWith("a"); // 过滤出以 a 为前缀的元素 }) .map(s -> { System.out.println("map: " + s); return s.toUpperCase(); // 转大写 }) .forEach(s -> System.out.println("forEach: " + s)); // for 循环输出 |
现在, map仅仅只需调用一次,性能得到了提升,这种小技巧对于流中存在大量元素来说,是非常很有用的。
接下来,让我们对上面的代码再添加一个中间操作 sorted:
1 | Stream.of("d2", "a2", "b1", "b3", "c") .sorted((s1, s2) -> { System.out.printf("sort: %s; %s\n", s1, s2); return s1.compareTo(s2); // 排序 }) .filter(s -> { System.out.println("filter: " + s); return s.startsWith("a"); // 过滤出以 a 为前缀的元素 }) .map(s -> { System.out.println("map: " + s); return s.toUpperCase(); // 转大写 }) .forEach(s -> System.out.println("forEach: " + s)); // for 循环输出 |
sorted 是一个有状态的操作,因为它需要在处理的过程中,保存状态以对集合中的元素进行排序。
执行上面代码,输出如下:
1 | sort: a2; d2sort: b1; a2sort: b1; d2sort: b1; a2sort: b3; b1sort: b3; d2sort: c; b3sort: c; d2filter: a2map: a2forEach: A2filter: b1filter: b3filter: cfilter: d2 |
咦咦咦?这次怎么又不是垂直执行了。你需要知道的是, sorted是水平执行的。因此,在这种情况下, sorted会对集合中的元素组合调用八次。这里,我们也可以利用上面说道的优化技巧,将 filter 过滤中间操作移动到开头部分:
1 | Stream.of("d2", "a2", "b1", "b3", "c") .filter(s -> { System.out.println("filter: " + s); return s.startsWith("a"); }) .sorted((s1, s2) -> { System.out.printf("sort: %s; %s\n", s1, s2); return s1.compareTo(s2); }) .map(s -> { System.out.println("map: " + s); return s.toUpperCase(); }) .forEach(s -> System.out.println("forEach: " + s)); |
从上面的输出中,我们看到了 sorted从未被调用过,因为经过 filter过后的元素已经减少到只有一个,这种情况下,是不用执行排序操作的。因此性能被大大提高了。
五、数据流复用问题
Java8 Stream 流是不能被复用的,一旦你调用任何终端操作,流就会关闭:
1 | Stream<String> stream = Stream.of("d2", "a2", "b1", "b3", "c") .filter(s -> s.startsWith("a")); |
当我们对 stream 调用了 anyMatch 终端操作以后,流即关闭了,再调用 noneMatch 就会抛出异常:
1 | java.lang.IllegalStateException: stream has already been operated upon or closed at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229) at java.util.stream.ReferencePipeline.noneMatch(ReferencePipeline.java:459) at com.winterbe.java8.Streams5.test7(Streams5.java:38) at com.winterbe.java8.Streams5.main(Streams5.java:28) |
为了克服这个限制,我们必须为我们想要执行的每个终端操作创建一个新的流链,例如,我们可以通过 Supplier 来包装一下流,通过 get() 方法来构建一个新的 Stream 流,如下所示:
1 | Supplier<Stream<String>> streamSupplier = () -> Stream.of("d2", "a2", "b1", "b3", "c") .filter(s -> s.startsWith("a")); |
通过构造一个新的流,来避开流不能被复用的限制, 这也是取巧的一种方式。
六、高级操作
Streams 支持的操作很丰富,除了上面介绍的这些比较常用的中间操作,如 filter或 map(参见Stream Javadoc)外。还有一些更复杂的操作,如 collect, flatMap以及 reduce。接下来,就让我们学习一下:
本小节中的大多数代码示例均会使用以下 List<Person>进行演示:
1 | class Person { String name; int age; |
6.1 Collect
collect 是一个非常有用的终端操作,它可以将流中的元素转变成另外一个不同的对象,例如一个 List, Set或 Map。collect 接受入参为 Collector(收集器),它由四个不同的操作组成:供应器(supplier)、累加器(accumulator)、组合器(combiner)和终止器(finisher)。
这些都是个啥?别慌,看上去非常复杂的样子,但好在大多数情况下,您并不需要自己去实现收集器。因为 Java 8通过 Collectors类内置了各种常用的收集器,你直接拿来用就行了。
让我们先从一个非常常见的用例开始:
1 | List<Person> filtered = persons .stream() // 构建流 .filter(p -> p.name.startsWith("P")) // 过滤出名字以 P 开头的 .collect(Collectors.toList()); // 生成一个新的 List |
你也看到了,从流中构造一个 List 异常简单。如果说你需要构造一个 Set 集合,只需要使用 Collectors.toSet()就可以了。
接下来这个示例,将会按年龄对所有人进行分组:
1 | Map<Integer, List<Person>> personsByAge = persons .stream() .collect(Collectors.groupingBy(p -> p.age)); // 以年龄为 key,进行分组 |
除了上面这些操作。您还可以在流上执行聚合操作,例如,计算所有人的平均年龄:
1 | Double averageAge = persons .stream() .collect(Collectors.averagingInt(p -> p.age)); // 聚合出平均年龄 |
如果您还想得到一个更全面的统计信息,摘要收集器可以返回一个特殊的内置统计对象。通过它,我们可以简单地计算出最小年龄、最大年龄、平均年龄、总和以及总数量。
1 | IntSummaryStatistics ageSummary = persons .stream() .collect(Collectors.summarizingInt(p -> p.age)); // 生成摘要统计 |
下一个这个示例,可以将所有人名连接成一个字符串:
1 | String phrase = persons .stream() .filter(p -> p.age >= 18) // 过滤出年龄大于等于18的 .map(p -> p.name) // 提取名字 .collect(Collectors.joining(" and ", "In Germany ", " are of legal age.")); // 以 In Germany 开头,and 连接各元素,再以 are of legal age. 结束 |
连接收集器的入参接受分隔符,以及可选的前缀以及后缀。
对于如何将流转换为 Map集合,我们必须指定 Map 的键和值。这里需要注意, Map 的键必须是唯一的,否则会抛出 IllegalStateException 异常。
你可以选择传递一个合并函数作为额外的参数来避免发生这个异常:
1 | Map<Integer, String> map = persons .stream() .collect(Collectors.toMap( p -> p.age, p -> p.name, (name1, name2) -> name1 + ";" + name2)); // 对于同样 key 的,将值拼接 |
既然我们已经知道了这些强大的内置收集器,接下来就让我们尝试构建自定义收集器吧。
比如说,我们希望将流中的所有人转换成一个字符串,包含所有大写的名称,并以 |分割。为了达到这种效果,我们需要通过 Collector.of()创建一个新的收集器。同时,我们还需要传入收集器的四个组成部分:供应器、累加器、组合器和终止器。
1 | Collector<Person, StringJoiner, String> personNameCollector = Collector.of( () -> new StringJoiner(" | "), // supplier 供应器 (j, p) -> j.add(p.name.toUpperCase()), // accumulator 累加器 (j1, j2) -> j1.merge(j2), // combiner 组合器 StringJoiner::toString); // finisher 终止器 |
由于Java 中的字符串是 final 类型的,我们需要借助辅助类 StringJoiner,来帮我们构造字符串。
最开始供应器使用分隔符构造了一个 StringJointer。
累加器用于将每个人的人名转大写,然后加到 StringJointer中。
组合器将两个 StringJointer合并为一个。
最终,终结器从 StringJointer构造出预期的字符串。
6.2 FlatMap
上面我们已经学会了如通过 map操作, 将流中的对象转换为另一种类型。但是, Map只能将每个对象映射到另一个对象。
如果说,我们想要将一个对象转换为多个其他对象或者根本不做转换操作呢?这个时候, flatMap就派上用场了。
FlatMap 能够将流的每个元素, 转换为其他对象的流。因此,每个对象可以被转换为零个,一个或多个其他对象,并以流的方式返回。之后,这些流的内容会被放入 flatMap返回的流中。
在学习如何实际操作 flatMap之前,我们先新建两个类,用来测试:
1 | class Foo { String name; List<Bar> bars = new ArrayList<>(); |
接下来,通过我们上面学习到的流知识,来实例化一些对象:
1 | List<Foo> foos = new ArrayList<>(); |
我们创建了包含三个 foo的集合,每个 foo中又包含三个 bar。
flatMap 的入参接受一个返回对象流的函数。为了处理每个 foo中的 bar,我们需要传入相应 stream 流:
1 | foos.stream() .flatMap(f -> f.bars.stream()) .forEach(b -> System.out.println(b.name)); |
如上所示,我们已成功将三个 foo对象的流转换为九个 bar对象的流。
最后,上面的这段代码可以简化为单一的流式操作:
1 | IntStream.range(1, 4) .mapToObj(i -> new Foo("Foo" + i)) .peek(f -> IntStream.range(1, 4) .mapToObj(i -> new Bar("Bar" + i + " <- " f.name)) .forEach(f.bars::add)) .flatMap(f -> f.bars.stream()) .forEach(b -> System.out.println(b.name)); |
flatMap也可用于Java8引入的 Optional类。Optional的 flatMap操作返回一个 Optional或其他类型的对象。所以它可以用于避免繁琐的 null检查。
接下来,让我们创建层次更深的对象:
1 | class Outer { Nested nested;} |
为了处理从 Outer 对象中获取最底层的 foo 字符串,你需要添加多个 null检查来避免可能发生的 NullPointerException,如下所示:
1 | Outer outer = new Outer();if (outer != null && outer.nested != null && outer.nested.inner != null) { System.out.println(outer.nested.inner.foo);} |
我们还可以使用 Optional的 flatMap操作,来完成上述相同功能的判断,且更加优雅:
1 | Optional.of(new Outer()) .flatMap(o -> Optional.ofNullable(o.nested)) .flatMap(n -> Optional.ofNullable(n.inner)) .flatMap(i -> Optional.ofNullable(i.foo)) .ifPresent(System.out::println); |
如果不为空的话,每个 flatMap的调用都会返回预期对象的 Optional包装,否则返回为 null的 Optional包装类。
笔者补充:关于 Optional 可参见我另一篇译文《如何在 Java8 中风骚走位避开空指针异常》
6.3 Reduce
规约操作可以将流的所有元素组合成一个结果。Java 8 支持三种不同的 reduce方法。第一种将流中的元素规约成流中的一个元素。
让我们看看如何使用这种方法,来筛选出年龄最大的那个人:
1 | persons .stream() .reduce((p1, p2) -> p1.age > p2.age ? p1 : p2) .ifPresent(System.out::println); // Pamela |
reduce方法接受 BinaryOperator积累函数。该函数实际上是两个操作数类型相同的 BiFunction。BiFunction功能和 Function一样,但是它接受两个参数。示例代码中,我们比较两个人的年龄,来返回年龄较大的人。
第二种 reduce方法接受标识值和 BinaryOperator累加器。此方法可用于构造一个新的 Person,其中包含来自流中所有其他人的聚合名称和年龄:
1 | Person result = persons .stream() .reduce(new Person("", 0), (p1, p2) -> { p1.age += p2.age; p1.name += p2.name; return p1; }); |
第三种 reduce方法接受三个参数:标识值, BiFunction累加器和类型的组合器函数 BinaryOperator。由于初始值的类型不一定为 Person,我们可以使用这个归约函数来计算所有人的年龄总和:
1 | Integer ageSum = persons .stream() .reduce(0, (sum, p) -> sum += p.age, (sum1, sum2) -> sum1 + sum2); |
结果为76,但是内部究竟发生了什么呢?让我们再打印一些调试日志:
1 | Integer ageSum = persons .stream() .reduce(0, (sum, p) -> { System.out.format("accumulator: sum=%s; person=%s\n", sum, p); return sum += p.age; }, (sum1, sum2) -> { System.out.format("combiner: sum1=%s; sum2=%s\n", sum1, sum2); return sum1 + sum2; }); |
你可以看到,累加器函数完成了所有工作。它首先使用初始值 0和第一个人年龄相加。接下来的三步中 sum会持续增加,直到76。
等等?好像哪里不太对!组合器从来都没有调用过啊?
我们以并行流的方式运行上面的代码,看看日志输出:
1 | Integer ageSum = persons .parallelStream() .reduce(0, (sum, p) -> { System.out.format("accumulator: sum=%s; person=%s\n", sum, p); return sum += p.age; }, (sum1, sum2) -> { System.out.format("combiner: sum1=%s; sum2=%s\n", sum1, sum2); return sum1 + sum2; }); |
并行流的执行方式完全不同。这里组合器被调用了。实际上,由于累加器被并行调用,组合器需要被用于计算部分累加值的总和。
让我们在下一章深入探讨并行流。
七、并行流
流是可以并行执行的,当流中存在大量元素时,可以显著提升性能。并行流底层使用的 ForkJoinPool, 它由 ForkJoinPool.commonPool()方法提供。底层线程池的大小最多为五个 - 具体取决于 CPU 可用核心数:
1 | ForkJoinPool commonPool = ForkJoinPool.commonPool();System.out.println(commonPool.getParallelism()); // 3 |
在我的机器上,公共池初始化默认值为 3。你也可以通过设置以下JVM参数可以减小或增加此值:
1 | -Djava.util.concurrent.ForkJoinPool.common.parallelism=5 |
集合支持 parallelStream()方法来创建元素的并行流。或者你可以在已存在的数据流上调用中间方法 parallel(),将串行流转换为并行流,这也是可以的。
为了详细了解并行流的执行行为,我们在下面的示例代码中,打印当前线程的信息:
1 | Arrays.asList("a1", "a2", "b1", "c2", "c1") .parallelStream() .filter(s -> { System.out.format("filter: %s [%s]\n", s, Thread.currentThread().getName()); return true; }) .map(s -> { System.out.format("map: %s [%s]\n", s, Thread.currentThread().getName()); return s.toUpperCase(); }) .forEach(s -> System.out.format("forEach: %s [%s]\n", s, Thread.currentThread().getName())); |
通过日志输出,我们可以对哪个线程被用于执行流式操作,有个更深入的理解:
1 | filter: b1 [main]filter: a2 [ForkJoinPool.commonPool-worker-1]map: a2 [ForkJoinPool.commonPool-worker-1]filter: c2 [ForkJoinPool.commonPool-worker-3]map: c2 [ForkJoinPool.commonPool-worker-3]filter: c1 [ForkJoinPool.commonPool-worker-2]map: c1 [ForkJoinPool.commonPool-worker-2]forEach: C2 [ForkJoinPool.commonPool-worker-3]forEach: A2 [ForkJoinPool.commonPool-worker-1]map: b1 [main]forEach: B1 [main]filter: a1 [ForkJoinPool.commonPool-worker-3]map: a1 [ForkJoinPool.commonPool-worker-3]forEach: A1 [ForkJoinPool.commonPool-worker-3]forEach: C1 [ForkJoinPool.commonPool-worker-2] |
如您所见,并行流使用了所有的 ForkJoinPool中的可用线程来执行流式操作。在持续的运行中,输出结果可能有所不同,因为所使用的特定线程是非特定的。
让我们通过添加中间操作 sort来扩展上面示例:
1 | Arrays.asList("a1", "a2", "b1", "c2", "c1") .parallelStream() .filter(s -> { System.out.format("filter: %s [%s]\n", s, Thread.currentThread().getName()); return true; }) .map(s -> { System.out.format("map: %s [%s]\n", s, Thread.currentThread().getName()); return s.toUpperCase(); }) .sorted((s1, s2) -> { System.out.format("sort: %s <> %s [%s]\n", s1, s2, Thread.currentThread().getName()); return s1.compareTo(s2); }) .forEach(s -> System.out.format("forEach: %s [%s]\n", s, Thread.currentThread().getName())); |
运行代码,输出结果看上去有些奇怪:
1 | filter: c2 [ForkJoinPool.commonPool-worker-3]filter: c1 [ForkJoinPool.commonPool-worker-2]map: c1 [ForkJoinPool.commonPool-worker-2]filter: a2 [ForkJoinPool.commonPool-worker-1]map: a2 [ForkJoinPool.commonPool-worker-1]filter: b1 [main]map: b1 [main]filter: a1 [ForkJoinPool.commonPool-worker-2]map: a1 [ForkJoinPool.commonPool-worker-2]map: c2 [ForkJoinPool.commonPool-worker-3]sort: A2 <> A1 [main]sort: B1 <> A2 [main]sort: C2 <> B1 [main]sort: C1 <> C2 [main]sort: C1 <> B1 [main]sort: C1 <> C2 [main]forEach: A1 [ForkJoinPool.commonPool-worker-1]forEach: C2 [ForkJoinPool.commonPool-worker-3]forEach: B1 [main]forEach: A2 [ForkJoinPool.commonPool-worker-2]forEach: C1 [ForkJoinPool.commonPool-worker-1] |
貌似 sort只在主线程上串行执行。但是实际上,并行流中的 sort在底层使用了Java8中新的方法 Arrays.parallelSort()。如 javadoc官方文档解释的,这个方法会按照数据长度来决定以串行方式,或者以并行的方式来执行。
如果指定数据的长度小于最小数值,它则使用相应的
Arrays.sort方法来进行排序。
回到上小节 reduce的例子。我们已经发现了组合器函数只在并行流中调用,而不不会在串行流中被调用。
让我们来实际观察一下涉及到哪个线程:
1 | List<Person> persons = Arrays.asList( new Person("Max", 18), new Person("Peter", 23), new Person("Pamela", 23), new Person("David", 12)); |
通过控制台日志输出,累加器和组合器均在所有可用的线程上并行执行:
1 | accumulator: sum=0; person=Pamela; [main]accumulator: sum=0; person=Max; [ForkJoinPool.commonPool-worker-3]accumulator: sum=0; person=David; [ForkJoinPool.commonPool-worker-2]accumulator: sum=0; person=Peter; [ForkJoinPool.commonPool-worker-1]combiner: sum1=18; sum2=23; [ForkJoinPool.commonPool-worker-1]combiner: sum1=23; sum2=12; [ForkJoinPool.commonPool-worker-2]combiner: sum1=41; sum2=35; [ForkJoinPool.commonPool-worker-2] |
总之,你需要记住的是,并行流对含有大量元素的数据流提升性能极大。但是你也需要记住并行流的一些操作,例如 reduce和 collect操作,需要额外的计算(如组合操作),这在串行执行时是并不需要。
此外,我们也了解了,所有并行流操作都共享相同的 JVM 相关的公共 ForkJoinPool。所以你可能需要避免写出一些又慢又卡的流式操作,这很有可能会拖慢你应用中,严重依赖并行流的其它部分代码的性能。
八、结语
Java8 Stream 流编程指南到这里就结束了。如果您有兴趣了解更多有关 Java 8 Stream 流的相关信息,我建议您使用 Stream Javadoc 阅读官方文档。如果您想了解有关底层机制的更多信息,您也可以阅读 Martin Fowlers 关于 Collection Pipelines 的文章。
最后,祝您学习愉快!