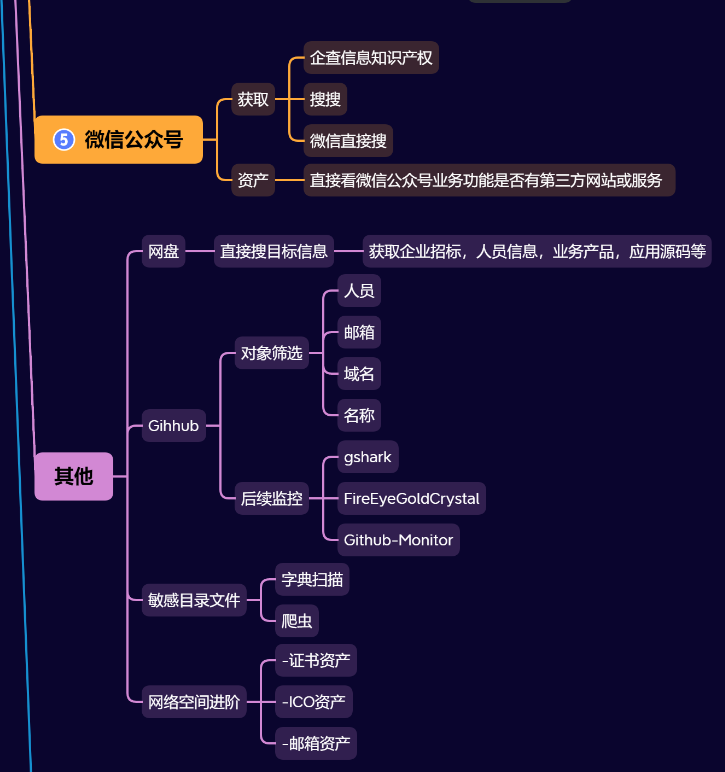
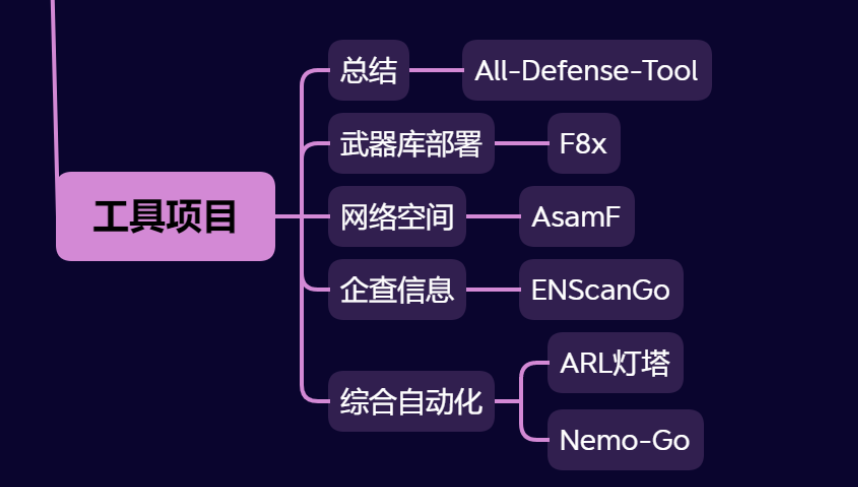
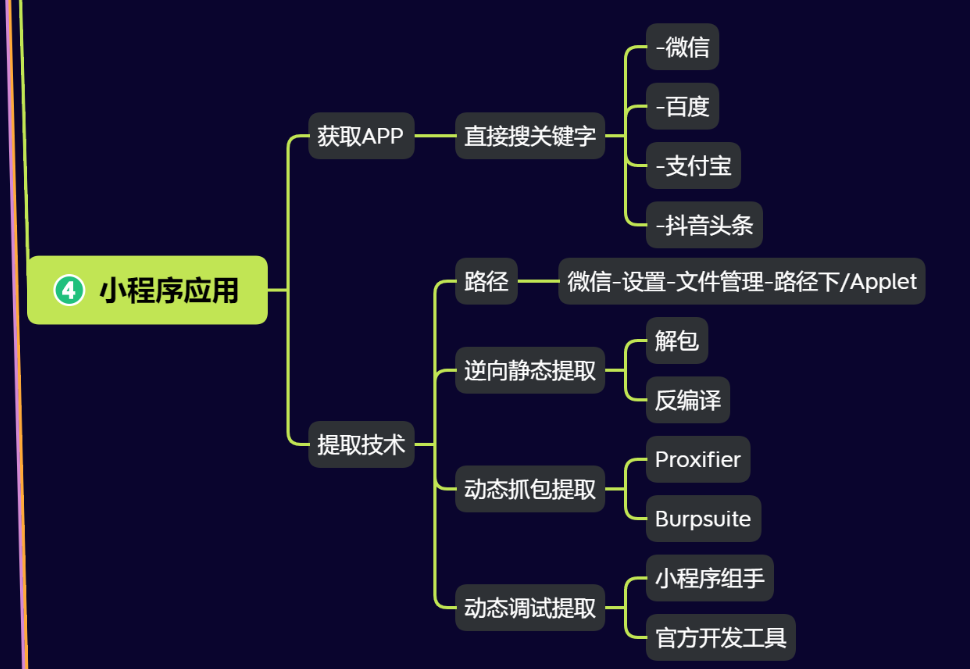
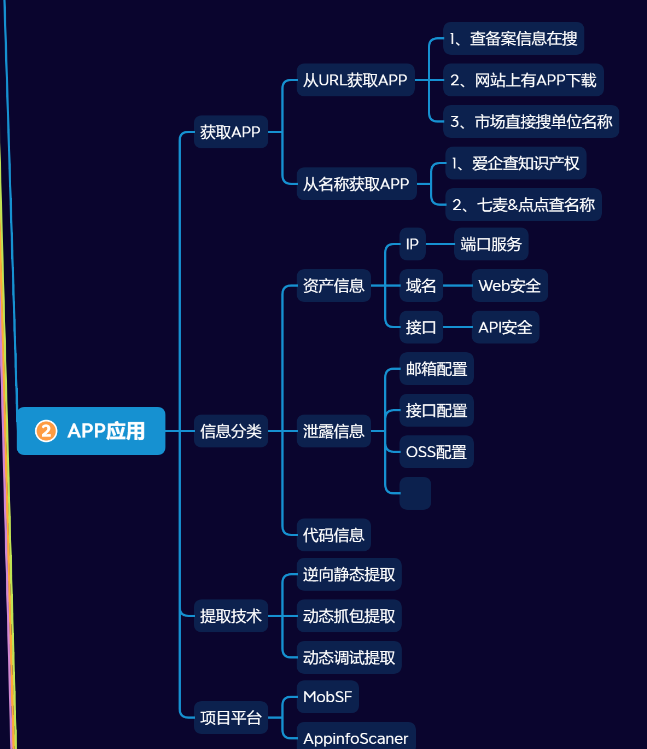
IK分词器安装
1、环境准备
Elasticsearch 要使用 ik,就要先构建 ik 的 jar包,这里要用到 maven 包管理工具,而 maven 需要java 环境,而 Elasticsearch 内置了jdk, 所以可以将JAVA_HOME设置为Elasticsearch 内置的jdk
1)设置JAVA_HOME
1
2
3
4
5
6
7
8
9
| vim /etc/profile
# 在profile文件末尾添加
#java environment
export JAVA_HOME=/opt/elasticsearch-7.4.0/jdk
export PATH=$PATH:${JAVA_HOME}/bin
# 保存退出后,重新加载profile
source /etc/profile
|
2)下载maven安装包
1
| wget http://mirror.cc.columbia.edu/pub/software/apache/maven/maven-3/3.1.1/binaries/apache-maven-3.1.1-bin.tar.gz
|
3)解压maven安装包
1
| tar xzf apache-maven-3.1.1-bin.tar.gz
|
4)设置软连接
1
| ln -s apache-maven-3.1.1 maven
|
5)设置path
打开文件
1
| vim /etc/profile.d/maven.sh
|
将下面的内容复制到文件,保存
1
2
| export MAVEN_HOME=/opt/maven
export PATH=${MAVEN_HOME}/bin:${PATH}
|
设置好Maven的路径之后,需要运行下面的命令使其生效
1
| source /etc/profile.d/maven.sh
|
6)验证maven是否安装成功
2、安装IK分词器
1)下载IK
1
| wget https://github.com/medcl/elasticsearch-analysis-ik/archive/v7.4.0.zip
|
执行如下图:
2)解压IK
由于这里是zip包不是gz包,所以我们需要使用unzip命令进行解压,如果本机环境没有安装unzip,请执行:
1
2
| yum install zip
yum install unzip
|
解压IK
3)编译jar包
1
2
3
4
| # 切换到 elasticsearch-analysis-ik-7.4.0目录
cd elasticsearch-analysis-ik-7.4.0/
#打包
mvn package
|
4) jar包移动
package执行完毕后会在当前目录下生成target/releases目录,将其中的elasticsearch-analysis-ik-7.4.0.zip。拷贝到elasticsearch目录下的新建的目录plugins/analysis-ik,并解压
1
2
3
4
5
6
7
8
9
| #切换目录
cd /opt/elasticsearch-7.4.0/plugins/
#新建目录
mkdir analysis-ik
cd analysis-ik
#执行拷贝
cp -R /opt/elasticsearch-analysis-ik-7.4.0/target/releases/elasticsearch-analysis-ik-7.4.0.zip /opt/elasticsearch-7.4.0/plugins/analysis-ik
#执行解压
unzip /opt/elasticsearch-7.4.0/plugins/analysis-ik/elasticsearch-analysis-ik-7.4.0.zip
|
5)拷贝辞典
将elasticsearch-analysis-ik-7.4.0目录下的config目录中的所有文件 拷贝到elasticsearch的config目录
1
| cp -R /opt/elasticsearch-analysis-ik-7.4.0/config/* /opt/elasticsearch-7.4.0/config
|
记得一定要重启Elasticsearch!!!
3、使用IK分词器
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
1、ik_max_word
会将文本做最细粒度的拆分,比如会将“乒乓球明年总冠军”拆分为“乒乓球、乒乓、球、明年、总冠军、冠军。
1
2
3
4
5
6
| #方式一ik_max_word
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "乒乓球明年总冠军"
}
|
ik_max_word分词器执行如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| {
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "乒乓",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "球",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "冠军",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
}
]
}
|
2、ik_smart
会做最粗粒度的拆分,比如会将“乒乓球明年总冠军”拆分为乒乓球、明年、总冠军。
1
2
3
4
5
6
| #方式二ik_smart
GET /_analyze
{
"analyzer": "ik_smart",
"text": "乒乓球明年总冠军"
}
|
ik_smart分词器执行如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| {
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
}
]
}
|
由此可见 使用ik_smart可以将文本”text”: “乒乓球明年总冠军”分成了【乒乓球】【明年】【总冠军】
这样看的话,这样的分词效果达到了我们的要求。